
LSM-Tree 结构化日志合并树
LSM Tree
从关系型数据库说起
传统关系型数据库通常在读性能上有较高的要求,通过在特定范围内进行复杂、简单读场景下进行高效的查找。
- 关系型数据库在读性能上有很高的要求(比如电商、金融通常人们说吞吐量、或者说查询太慢)。
- 关系型数据库在一定程度的数据规模下能够支持事务、快速的在线联机处理,在特定的复杂查询场景下能够高效的检索。
- 二分查找、hash、索引、B+树信息强加在了数据上,数据必须按照特定的方式存储。这样就有一个缺陷就是涉及到了磁盘的随机写。逻辑上很近的数据物理上可能很远,就可能造成大量的磁盘随机写,严重影响写操作性能。
总结: 关系型数据库相比较看重的是读性能。通过二分查找、hash、B+树等是数据查询更快,但是底层磁盘的存储造成了大量的随机写。虽说电商、金融等行业业务数据量大、但是针对我们后端接口等操作的适合只是其中部分具有固定场景的查询(索引、where)。
LSM Tree 特性
因为磁盘随机操作慢,顺序读写快的特性,如果要提高写操作性能,避免随机写,设计成顺序写。
顺序写简单,直接将数据追加的方式写入文件,因为完全是顺序的,所以性能很好。
但是读取却要花费很多时间。因为查询具体的内容需要扫描所有数据。通过上述分析得出如果要高效的读和写其实要根据具体的场景做一个权衡。所以LSM-Tree诞生了。
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用磁盘批量的顺序写要远比随机写性能高出很多。
发挥磁盘的特性:一次性地读取或写入固定大小的一批数据,并尽可能地减少随机寻道操作。
LSM-Tree 结构除了利用磁盘顺序写实现高性能写,也通过划分内存+磁盘的多层合并结构及各种优化实现尽量保证读性能。
传统关系型数据库查询的一般将数据库当作一个整体去查找我们想要的数据, 但LSM 树通过这些有序文件实现了(管理一组索引、快照文件而不是单一的索引文件,并且推迟和批量地进行数据更新),充分利用内存来存储近期或常用数据以提高读效率,索引、快照文件也是按照时间顺序来存储数据(这也是为什么paimon、hudi通过spark、flink做实时依然很快),利用硬盘存储不常用数据以减少存储代价。
- 利用磁盘顺序写块的特性,将数据以追加的方式写入到文件系统,同时维护多个索引、快照文件。
- 数据的更新不是直接更新数据,而是写入到文件,新老数据有版本的概念。
- 查询的数据如果在CN层就会很慢(paimon中讲解优化)
写数据流程
1. 写数据操作触发,首先将数据记录在写前日志(Write Ahead Log),以便故障时恢复数据
2. 把数据追加到内存中的 C0 层
3. 当 C0 层的数据量达到一定大小,就把 C0 层 和 C1 层以归并排序的方式合并,这个过程被称为 Compaction(合并)。合并出来的新的文件会顺序写磁盘,替换掉旧的文件。当 C1 层达到一定大小,会继续和下层合并,合并之后所有旧文件都可以删掉,留下新的
4. 需注意数据的写入可能重复,新版本需要覆盖老版本。比如先写(a=10),再写(a=666),666 就是新版本数据。假如 a 老版本已经到 Ci 层了, C0 层来了个新版本,这时不会去更新下层文件中的老版本记录,而只在 C0 层写一个新的数据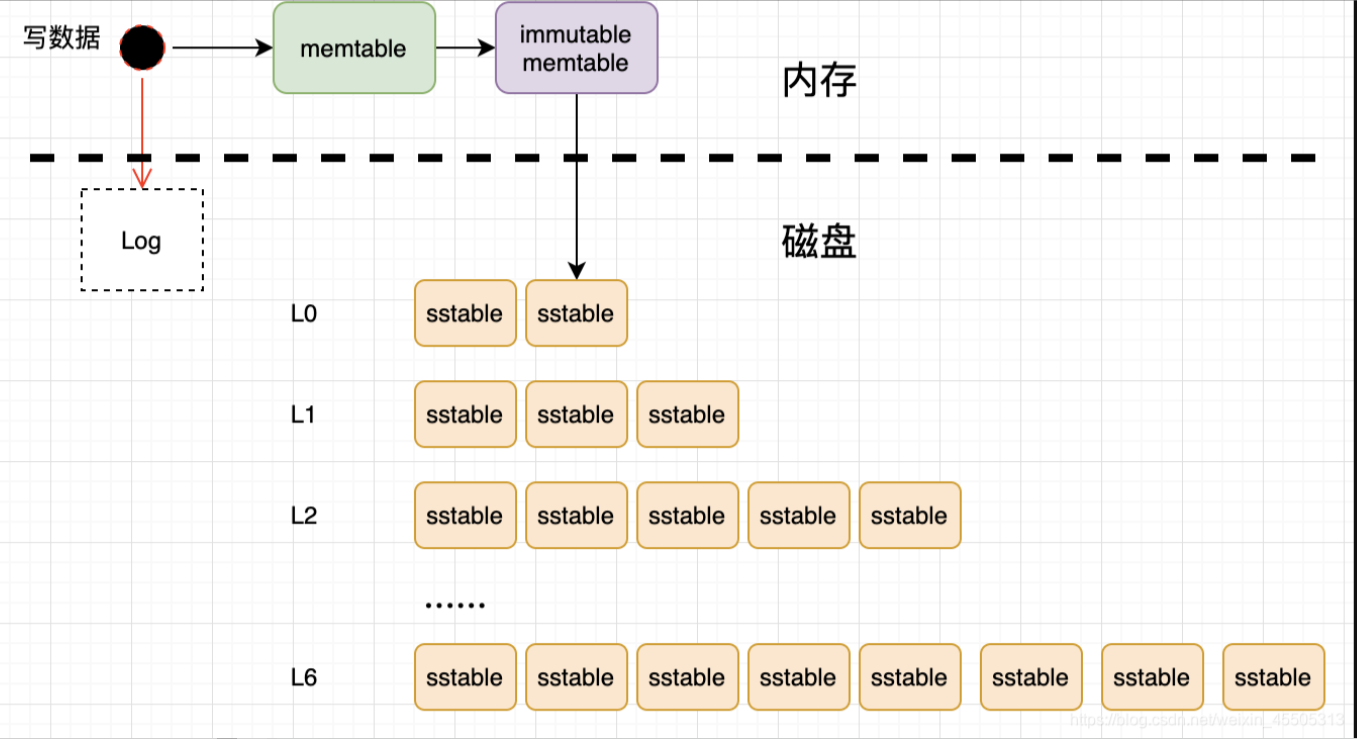
Paimon Sorted Run
Paimon 采用 LSM 树(日志结构合并树)作为文件存储的数据结构。 LSM 树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run。 数据文件中的记录按其主键排序。在Sorted Run中,数据文件的主键范围永远不会重叠。
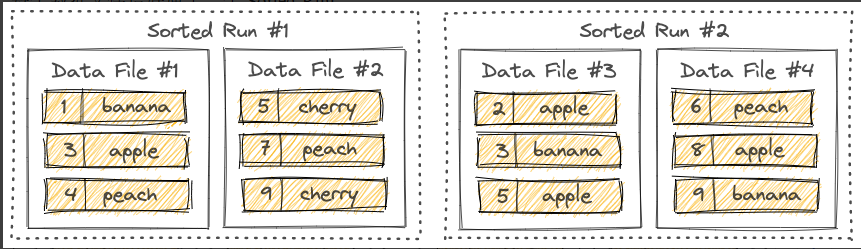
正如您所看到的,不同的Sorted Run可能具有重叠的主键范围,甚至可能包含相同的主键。查询LSM树时,必须合并所有Sorted Run,并且必须根据用户指定的合并引擎和每条记录的时间戳来合并具有相同主键的所有记录。 写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
Paimon Compaction
1.小文件合并,提高查询效率
当越来越多的记录写入LSM树时,Sorted Run的数量将会增加。由于查询LSM树需要将所有Sorted Run合并起来,太多Sorted Run将导致查询性能较差,甚至内存不足。 为了限制Sorted Run的数量,我们必须偶尔将多个Sorted Run合并为一个大的Sorted Run。这个过程称为Compaction。
2.Compaction也会影响效率 Compaction虽然会解决小问题的问题,但是合并本身会读取历史数据,消耗CPU和磁盘IO。因此如果合并处理频繁、定时合并设置不合理会导致速度越来越慢,带来很大的资源消耗。如果有离线任务在读取当前表也会影响整体效率。因此在查询和写入之间要做一个衡量。 Paimon 目前采用的Compaction策略,Paimon将记录追加到LSM树时,它也会根据需要执行Compaction。用户还可以选择在“专用Compaction作业”中独立执行所有Compaction。
Hudi Compaction
./bin/flink run \
-c org.apache.hudi.sink.compact.HoodieFlinkCompactor \
lib/hudi-flink1.17-bundle-0.15.0.jar \
--path hdfs://lakehouse/table \Paimon Compaction
Flink SQL目前不支持compaction相关的语句,所以我们必须通过flink run来提交compaction作业。
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
compact \
–warehouse \
–database \
–table \
[–partition ] \
[–catalog-conf [–catalog-conf …]] \
如果提交一个批处理作业(execution.runtime-mode:batch),当前所有的表文件都会被Compaction。如果您提交一个流作业(execution.runtime-mode: streaming),该作业将持续监视表的新更改并根据需要执行Compaction。HBase,MongoDB 等存储引擎都是 LSM-Tree,kafka 用到了磁盘顺序读写大于随机读写的特性